Optimising webapps for high read density
Nearly all webapps deliver content from server to browser. Users interact with this content to gain whatever value they need. Let's optimise for this. 26 April 2022
# Read density
Many web applications like blogs and e-commerce sites, even dashboards experience high read density, hereby defined as reads per unit time. A read can be in the form of additional/alternative content in the same page/URL, or navigating to a new page/URL. Yet, something as simple as reading data can be quite nuanced and difficult to get right over high latency networks. This is made worse when there are long chains of data dependencies.
For example, a chain of questions need to be resolved when a user lands on a page. Who is the current user? What's their preferred language? What content in the preferred language should appear? What other content is related? Unless this is a large multi-table join, it is very likely that these need to be sequentially resolved.
On the one hand, if the resolution happens client-side, then each link in the chain adds another network round trip. On the other hand, if it happens server-side, then possibly no data is available on the client, until all data is available. Both result in poor user experience.
To give the best user experience, data needs to be streamed. Early data, or in the case of parallel requests, fast data, should be delivered as soon as it is available, even whilst the rest of the stream is being generated.
# Organising the timeline
Streaming is not new. Images can be streamed with formats like progressive JPEG, which provides increasingly higher resolutions as the file is streamed. Audio and video files, which are consumed in time-order obviously stream in time-order too. Importantly, browsers are capable of streaming HTML, rendering partial documents despite missing closing tags.
Typically, the first few hundred bytes of a HTML document are statically known, and can contain the location of related assets like CSS and JS. Returning this immediately gives the browser the opportunity to download them early (eg, using <script async>) whilst the server is still awaiting data for the remainder of the page.
The stream can be paused upon a fragment that is still awaiting data, and then resumed when the data is resolved. The process repeats until the last fragment is resolved. During this process, the user gradually sees more and more of the document.
Instead of pausing, alternative content such as placeholders can be sent without blocking the rest of the stream. This can later be reordered using Javascript or even CSS to preserve the same visual order, despite being out of order in the streamed HTML document. This increases overall complexity, and doesn't actually increase real performance but can be useful in some scenarios to increase perceived performance.
Consider the following timelines. The top two rows show typical CSR (Client Side Rendered) timelines. Both are hampered by an expensive initial load, as the browser loads heavy Javascript bundles. In the 1st row, the client makes data requests sequentially, and pays the network latency price on each link in the chain. In the 2nd row, the server helps out to resolve all the data requests, and so saves on the network latency. But why wait for the client to request the data at all? The bottom two rows show typical SSR (Server Side Rendered) timelines. In the 3rd row, the HTML is rendered once all data is resolved. Improving on this, the 4th row streams HTML fragments as soon as the backing data is resolved.
With streaming, the initial response is many times faster, and the total response time is just slightly longer than the time taken to resolve the data.
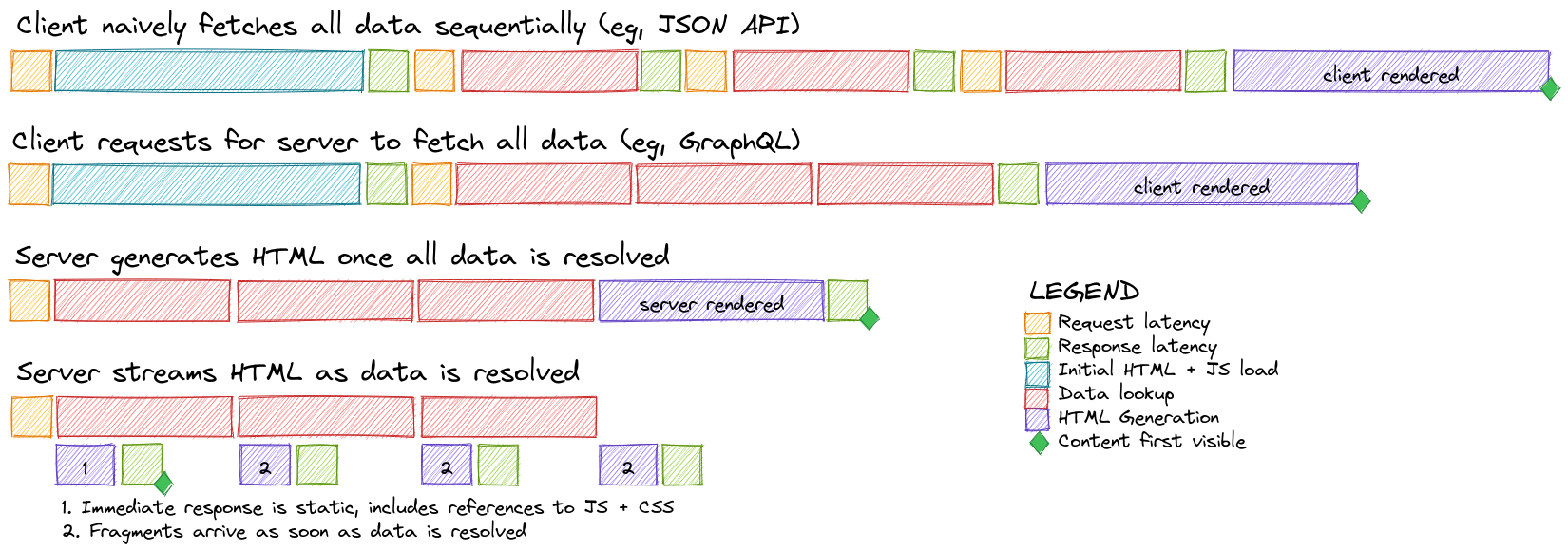
Even on subsequent data loads, where the initial HTML + JS load does not exist, the CSR timelines will never be as fast as with streaming HTML. This hints towards using a streaming architecture for optimal performance in applications with high read density.
Most data stores are fundamentally stream-friendly. For optimal end-to-end performance, stream-friendly backend formats like ND-JSON or ProtoBuf should be preferred over blocking / batching formats like JSON or GraphQL. Streaming is good for backend performance too, as it keeps memory consumption low, and allows back-pressure to be applied.
# Trimming excess fat
There is opportunity to significantly reduce code and execution complexity by rendering all of the HTML on the server. The server can generate personalised and internationalised HTML. It can generate signed URLs safely. It can generate CSRF tokens for increased security. The browser is no longer responsible for fetching data in non web-native formats (like GraphQL or even JSON). It no longer needs to render skeleton screens or error screens. It no longer needs to hijack and rewrite native routing and history capabilities. The only Javascript needed in the browser is that needed to create ephemeral DOM elements in response to user action, ie, to create interactive experiences.
Consider the following diagrams of a component tree. With full-tree hydration, every component needs to be client (re)rendered, even if it never changes. This requires not only code to render the component, but also its corresponding backing data. The entire tree is rendered once in the browser (repeating the server's work), and upon subsequent changes, followed by either a Virtual DOM to reconcile changed DOM nodes like React , or a runtime reactive graph to determine the required changes like Solid.js .
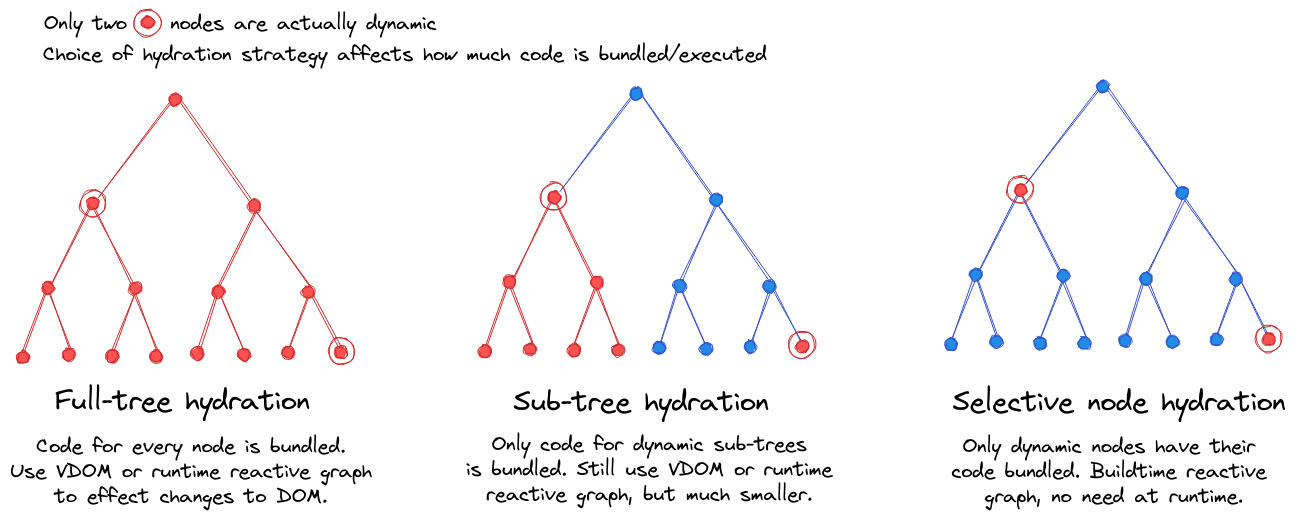
This can be improved with sub-tree hydration, by identifying only sub-trees that need to be updated. Static parts of the tree do not require component code nor backing data serialised to the browser, significantly reducing the size of both Javascript and HTML. Finally, selective-node hydration takes this further, surgically updating only the required DOM nodes on state changes.
Different frameworks approach this problem differently. React Server Components require developers to manually identify which components are server or client (but will warn if it's not correct). It also comes with the cost of increasing the base vendor code. Marko 5 automatically builds the sub-tree at build-time, while its successor Marko 6 and Qwik takes a fine-grained approach to bundle sub-components.
When used with streaming HTML, we can't wait for the entire HTML document with <script defer>. Fragments need to be interactive as soon as they stream in. The browser already handles this correctly for native elements like <a href>, <details>, or <input> tags. But non-native custom components like carousels or modals require custom code. For example, Marko inserts the framework runtime as a <script async> in the HTML head, and inlines the fragment specific code in the HTML as the fragments stream in. And Qwik inlines the framework runtime, and downloads the fragment specific code on-demand, achieving constant time-to-interactive regardless of application complexity.
# Leaning on browser capabilities
Finally, let's sanity check to ensure that the shipped Javascript is even necessary.
Browsers know how to GET pages. It knows how to display a native spinner when the page is still loading. With HTML streaming, there's even an implicit vertical "progress bar" that completes when the page is fully rendered. During loading, users can elect to abort at anytime. And if there are errors, browsers already have familiar error pages to tell the user what is wrong, and suggest ways to handle it. Hijacking browser navigation with client-side routing requires all of these to be reinvented in Javascript. This shouldn't be necessary.
Browsers know how to POST/GET forms. It knows how to collect data in accessible input fields, and submit the results in application/x-www-form-urlencoded or multipart/form-data encoding. Instead of hijacking these and replacing it with formats like GraphQL or even JSON, which requires writing code, consider progressively enhancing the native form submission with Javascript. This way, the application can be used even without Javascript, increasing its robustness against faulty networks, buggy browser plugins, even bad code deploys!
Browsers know how to prioritise asset loading. It knows how to prioritise the loading order of external assets such as CSS, fonts, and Javascript. With streaming HTML, it can even do this whilst the HTML is still loading. Capabilities like preload and fetchpriority allow developers to customise this. Hidden content can also be deferred with <img loading=lazy> and <iframe loading=lazy>. Reimplementing these in Javascript is not-only unnecessary, but it is not SEO friendly, as semantic intent is lost.
Modern browsers know how to use newer Javascript and web platform features, and most users are on modern browsers. For this majority, there's no need to limit them to older ES5 capabilities and bundle unnecessary polyfills. Having multiple build-time bundles, selectively chosen at runtime allows the majority to use slimmer bundles, while the minority on older browsers can still use the intended functionality, albeit with slightly larger bundles.
# Write density
In earlier drafts of this article, I initially segmented apps as mostly read, ie, content consumption vs mostly write, eg, content creation. But I soon realised that with the latter, you can still have one class that is read-light, and another class that is read-heavy; to get references, point to existing content, etc.
That's when I concluded that write density is a different problem entirely, independent of read density. Where reading has a lot to do with streaming partial content to the user as fast as possible whilst fetching more data, writing has more to do with optimistic UI to unblock the next user interaction as fast as possible. Perhaps more in a different article…
# Conclusion
For apps with high read density, which is the majority of web applications, the bottleneck is often in data loading. This can only be solved with HTML streaming, which points towards server rendered HTML. The next bottleneck is often the Javascript bundles. Techniques like selective node hydration can significantly reduce the size of the bundle to download and evaluate. This makes it kinder to slow networks and older slower devices.
This paints a picture that is practically the opposite of SPAs (Single Page Applications). Heavy Javascript on the browser pulls in non-streamable data, often with additional non-native GraphQL, meaning more Javascript. Reinventing browser navigation, and full client-side rendering means heavy bundles that perform poorly on slow networks and older slower devices. Code-splitting and lazy-loading can help, but these are really additional complexity used to disguise endemic complexity.
It is unfortunate that SPAs have dominated developer (and non-developer) mindshare over the last decade or so, such that its use has spread into areas well outside of its niche. But such is hindsight. The SPA revolution lowered the barrier to entry, and spawned new ways of thinking, some of which made its way into server rendered frameworks.
# Addendum
When are Single Page Applications the optimal choice? I can think of only two scenarios. Firstly, when there is a low read density, which essentially means an offline-oriented app, able to operate for long periods with no backing support from a server runtime. Secondly, when you're trading off the performance budget for the server runtime budget, as static websites are cheap to host.